Query Tuning in SQL: Fixing Instance-CPU Consumption Issue
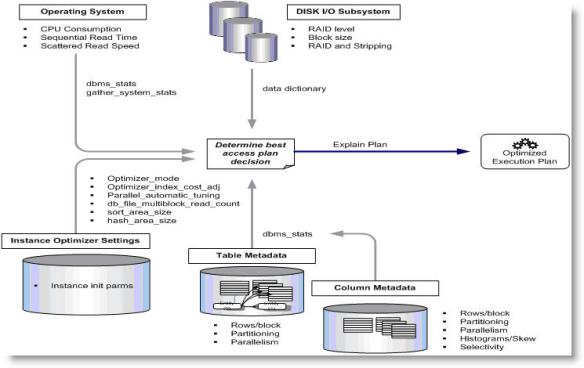
There are several SQL Server hosts containing numerous instances while a database management system operates. These instances consume resources - some of them significantly more than others - causing CPU issues.
However, it can be difficult to locate the exact cause of this problem while performing query tuning in SQL. In this article, we will uncover which SQL Server instance is taking up most of the CPU resources.
A common indicator of excess CPU pressure is when one or more applications run too slow, so get it checked by a professional if you face such an issue. It is easier for them to detect what's wrong by logging into the database server.
Here's what they do when they have multiple SQL instances running on the database and they have to determine which one among them is utilizing the maximum resources:
The first step is to open the Task Manager to check the database server's CPU usage. You will be able to locate all the executables and their CPU usage here. If all of them show the same percentage, a quick option at this point to find the culprit is to operate every instance using a separate domain account, such as SQLTest or SQLDev.

However, if they're all running under a single domain account, we would have to perform the next step - adding the PID or process identifier column in the task manager.
Every process getting executed on the system has a Process Identifier or PID assigned to it in Windows. You only have to enable that column by making sure the "Processes" tab is visible and clicking on the "Select Process Page Columns" section from the View option to select the PID option.
After you have clicked on the PID checkbox, click OK to save your changes and return to the Processes window of the Task Manager so you can resume database query optimization.
Now, you will be able to look at the unique PID of every 'sqlservr.exe' process - and find out how much CPU resources each one is consuming. Once we're able to do this, the next step is to uncover the exact SQL Server instance that is behind the PID, which we can do with the help of two simple ways.
The first method involves opening the SQL Server configuration manager, whereas the alternative is to take a look at the SQL Server error log.
Note: Earlier versions of the SQL Server - SQL Server 2000 and older - didn't have straightforward techniques to locate the PID for SQL Server instances. These methods were made available through the SQL Server manager from SQL Server 2005 onwards.
The next step in the path towards query tuning in SQL, and after finding the PID or the Server process ID, and the exact SQL Server instance that has the particular PID, is to open the SQL Server error log. This is because every time a SQL Server instance is created, the server process ID provided to that instance is recorded in this log. Moreover, this information is among the initial entries recorded in the error log.
If you wish to find the right PID of each SQL Server instance using the SQL Server configuration manager, simply launch the same and select the option that says "SQL Server Services", it is likely to be located on the top left side of the menu. Right next to it, you will be able to spot the PID numbers linked to each and every instance.

Using the information you have just gathered, you can determine which instance is taking up the most resources during query performance tuning. All you have to do now is correlate the data collected from Windows Task Manager and the application you chose among the SQL Server configuration manager and the SQL Server error log.
Database Query Optimization: When Hardware Should be Upgraded

One question that consultants are frequently asked is whether it is better to focus on upgrading hardware or optimizing software.
Here, we’ll analyze this question from the consultants’ point of view and understand why they suggest a hardware upgrade instead of software or database query optimization.
5 Questions to Ask before Making a Recommendation
Generally, consultants ask their clients the following questions before they suggest anything -
Question 1 - What is the state of the hardware?
In many cases, the hardware is inadequate, which is why upgrading it before hiring professional services is often much cheaper. However, some people may still prefer an optimized system, even if it will be run in seriously lacking hardware and prove more expensive.
If you require a significant performance boost but lack the time for major application changes, it may be more favorable to opt for a hardware boost in the long run.
Question 2 - Is current hardware usage balanced ?
Suppose you are conducting SQL performance monitoring for your organization’s database. You have five servers out of which one is overloaded and the remaining four are nearly idle. This is where it is more important, and sensible, to maintain a proper balance instead of blindly going for more hardware.
Of course, some of the applications may prove difficult to balance. Yet the number of cases with users suffering because of wrong balance, despite having reasonable sharded or replicated architecture, is astonishing. Furthermore, balancing could be a simple operations act or need certain application switches, depending on the situation.

Question 3 - Are there any fluctuations in hardware use?
Certain performance related issues can be unavoidable, such as during nightly backup or in case of a running cron job. In situations like these, it is better and more convenient to even out the usage rather than opt for a hardware upgrade.
Question 4 - What is the state of MySQL, Queries, and Architecture?
A hardware upgrade is not the first thing that consultants advise, especially if the user can triple performance with a basic my.cnf modification. For optimal performance, however, there is a need to see how easily the consultant and the client can balance everything through tasks like query performance tuning.
For instance, adding an index is simple, as is changing the statement in your own application. On the other hand, doing the same via third party applications is difficult, particularly for close source. Major schema modifications, caching, sharding, etc. could get complicated or remain relatively simple, depending on the specific case.
The larger your application will turn out to be the better you’ll want its performance to be on application level.
Question 5 - What do you hope to achieve with the hardware upgrade?
Having a goal is just as important here as it is in the case of software optimization. Memory is inserted to prevent disk IO and quicken lookups, and for database query optimization, you add indexes to prevent a complete table scan and improve the speed of the related query.
The aim of application performance optimization is to improve throughput, speed up statement execution. In a similar manner, these should be kept in mind when you consider upgrading your hardware -
- Quicker random IO,
- Enhanced caching,
- Rapid execution
Such factors will help you keep things in perspective in order to comprehend what needs to be done, such as opting for a new SSD, or upgrading memory and CPUs. You will have to resolve certain balancing questions on the way, but having a goal before you begin will help you achieve better performance in a more satisfactory manner.

Why Performance Tuning SQL Requires Looking Out for CRON Jobs

Intense database overload can have many reasons, one of which is a large number of cron job copies running at the same time. Naturally, an unusually large number of cron jobs will have an extreme effect on database performance. In case the database server slows down or a job requires a longer time to complete than usual, so much that it is still running when its second copy begins running, resulting in the two jobs competing with each other for resources and further reducing the chances of completing.
How to Handle the Multiple Cron Jobs Problem - and Improve Database Performance
Although such a dramatic effect is often noticed and resolved well in time, it can get quite frequent at times, hence the need for Performance Tuning Sql MySQL. Here, we will discuss a few ways to help users keep their cron jobs under control.
1. Avoid Running Several Copies
This one’s apparent and can be done quite easily. Experts suggest leaving the “production requirement” of zero cron jobs permitted, except when they keep themselves from initiating in several copies or be placed in a wrapper script around jobs constructed by developers as they are entered in production.
File locks are especially helpful in this case - refrain from creating files without them, otherwise those remaining post a script crash may keep it from restarting. You may also use the GET_LOCK function in your MySQL queries before you begin tuning.
The second alternative may be preferable in case you wish to serialize jobs from several servers. It may also be useful if you require restrictions on concurrency for some processes for better performance. For instance, you have fifty web servers that run some cron jobs but you may not want over four of those servers to run those jobs at the same instance.

2. Keep an eye out for errors
One of Cron’s prominent features is mailing users the output. Changing the script to print only error messages can help you catch errors when they start to occur when you try performance tuning SQL, such as if a job fails to execute due to another unexpected job running in the system.
In big systems, there might be a slightly altered approach to this issue in order to prevent numerous cron job messages during database/server reboot, but at least you will be informed about cron errors in time.
3. Save Previous Run Times
Several instances have occurred where a Cron job couldn’t finish on time any more. There may be speculation regarding the reason behind this - whether the failure to complete occurred suddenly or if the job slowed down gradually till it just couldn’t finish in time.
In such cases, you may create a table in the database and save details regarding the cron job and the time it took to run to help you in query optimization later. This can also be recorded using a wrapper script but it’s best done internally, because you can store multiple metrics this way.
For instance, you could save information in this manner:
- Time taken = 30 seconds
- Images processed = 2000
When you start logging details in this manner, you can easily identify the reason behind the increase in time, such as a greater amount of work or slower system speed in completing the work. Hooking up monitoring to the trending information will be even more helpful, so you will be alerted when the cron job you’re recording data for takes five minutes to run instead of the usual 15 seconds.

SQL Performance Tuning: Finding Duplicate & Redundant Indexes
 In this blog, we’ll cover redundant and duplicate indexes, which are quite common in applications and affect database performance.
In this blog, we’ll cover redundant and duplicate indexes, which are quite common in applications and affect database performance.
An index is duplicated when there is more than one defined on a single column. Such indexes may have varying names or keywords used to define them at times. A common instance may be something like PRIMARY KEY(iden), UNIQUE KEY iden(iden), KEY iden2(iden).
How Duplicate Indexes are Created - and Found
These are often found during SQL performance tuning, and many users do this because they intend to use primary key as object identifier, after which they create the unique key to, well, keep the data unique. This is followed by a third KEY that can be utilized in the queries.
It’s a wrong practice in general because it slows down MySQL. Besides, creating a PRIMARY KEY is simply enough as it will enforce unique values and be used in the queries.
Another possible reason for creating several keys for the same column is that the user created the new ones without realizing there was a key already created for that column. This is something to be careful about in Oracle database and SQL, because MySQL allows users to create multiple indexes, which is rather lenient for users but can lead to performance issues in the future.
Moreover, these extra keys also require space on the disk and the memory as they will be stored inside the storage engine, and will require updating during data manipulation commands (update, insert, delete) in Oracle database and SQL. In short, duplicate indexes are bad news, so users need to remove them as soon as they find any of them.
Redundant Indexes: Why You Need to Get Rid of Them Too
Redundant indexes are often called BTree indexes by some experts, and the reason behind this can be understood by the following example:
KEY(X), KEY (X,Y), KEY(X(15))
Here, the first and last indexes are redundant. This is because they can be considered the prefix of the middle index, i.e., KEY(X,Y), which is why such indexes are given the nickname BTree indexes.
Queries that use these redundant indexes can also use longer indexes, which will result in poor performance, and the subsequent need for SQL performance tuning. Redundant indexes, therefore, also need to be eliminated at the first opportunity.
However, there are situations where this type of indexes actually prove useful, such as in the case of a significantly longer index. For instance, if X is integer and Y is varchar(295), it may hold several lengthy values using KEY(X) in a quicker manner than it would using KEY(X,Y).
Some cases, therefore, may require additional consideration before deciding to remove the redundant indexes. A typical instance where you may leave out shorter indexes and include longer ones may be in cases where you want a query to execute as a query covered by an index (to fetch every column from the index, say). Such indexes are usually too long for efficient application by other queries.
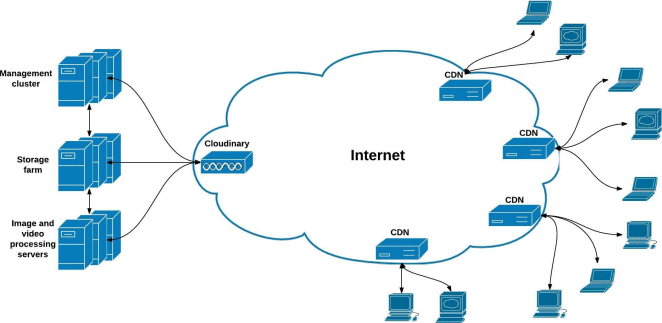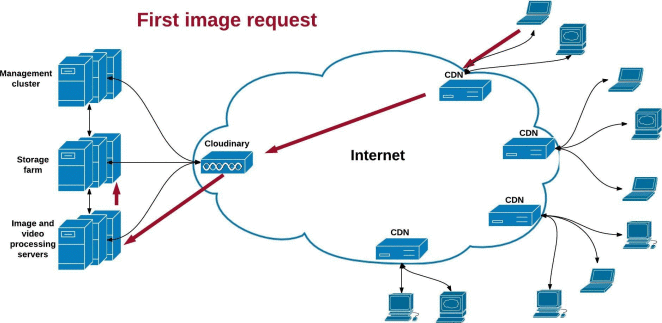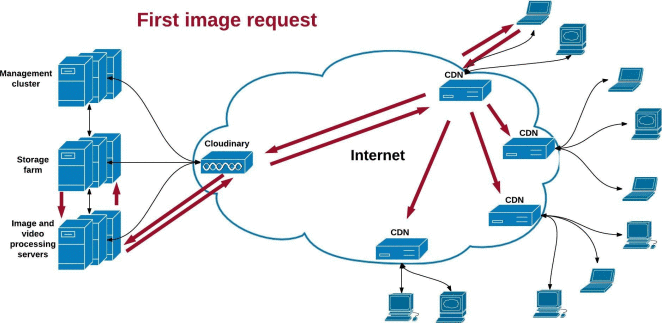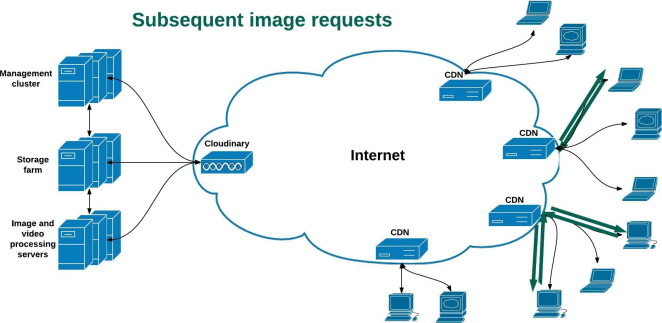
Query Performance Tuning: Why We Must Consider Partitions

How many partitions can one have in MySQL? As a DBA, you may face this question sooner or later, either as a hypothetical one or as an interesting case in a real-world scenario. What if a client dealing with a huge MySQL data warehouse has a table with data combined through INSERT ON DUPLICATE KEY UPDATE queries?
As one might expect, the result would be an extremely slow performance, thanks to the creation of numerous daily partitions for the table. Additionally, every statement faces a different impact, but the database would require query performance tuning regardless.
Optimization in SQL - Keep a Check on the Number of Partitions
Suppose you create the following test table -
CREATE TABLE `p10` (
`identity` int(10) unsigned NOT NULL,
`cust` int(10) unsigned NOT NULL,
PRIMARY KEY (`identity`),
KEY(cust)
) ENGINE=InnoDB
PARTITION BY RANGE(identity) (
PARTITION p100000 VALUES LESS THAN(100001),
PARTITION p200000 VALUES LESS THAN(200001),
.
.
.
.
.
.
PARTITION p900000 VALUES LESS THAN(900001),
PARTITION p1000000 VALUES LESS THAN(1000001)
);
……………………………….
CREATE TABLE `p10` (
`id` int(10) unsigned NOT NULL,
`c` int(10) unsigned NOT NULL,
PRIMARY KEY (`id`),
KEY(c)
) ENGINE=InnoDB
PARTITION BY RANGE(id) (
PARTITION p100000 VALUES LESS THAN(100001),
PARTITION p200000 VALUES LESS THAN(200001),
.
.
.
.
.
.
PARTITION p900000 VALUES LESS THAN(900001),
PARTITION p1000000 VALUES LESS THAN(1000001)
);
If you vary the quantity of partitions between one and thousand, following it up by loading the table full of a million sequential values ranging from one to a million with the help of bulk insert queries (adding a thousand to every column), here’s how much time it’ll take to load that information -
-
9.5 seconds for a single partition
-
10.5 secs for ten partitions
-
16.8 secs for a hundred partitions
-
24 secs for a thousand partitions
In other words, loading slows down by at least 2.6 times with an increase of a thousand in the quantity of partitions. When you attempt optimization in SQL, this seems surprising because only one out of a maximum of two partitions are actually having data insertions in each insert statement.
Such regression only increases if you test the UPDATE query as INSERT ON DUPLICATE KEY UPDATE set c=c+1 to the bulk inserts. In fact, it was observed that -

-
A single partition insertion took 51 seconds
-
Ten partitions took over 53 seconds
-
A hundred partitions consumed 73 seconds
-
A thousand partitions took over 293 seconds
The pattern has shifted slightly here in terms of performance loss - it has gotten almost 1.5 times slower, worsening with the jump from 100 to 1000 partitions.
Again, the difference increases once you eliminate an index on column C. The UPDATE aspect of the INSERT ON DUPLICATE KEY UPDATE query takes 23 seconds for a single partition and over 250 for a thousand partitions – which is more than ten times the difference - calling for a much-needed performance tuning in SQL Oracle.
This problem is caused in both MyISAM and InnoDB. In MyISAM, the Update path for in the absence of indexes took 11 seconds for one partition and over 53 seconds for a thousand partitions.
What Lead to Such Drastic Results, Requiring a Performance Tuning in SQL Oracle?
There are a few suspects here. One of them is the “setup” expense of the query that prepares all the partitions for execution, and the other could be the time taken to perform this for each row - the “per row” cost.
When we wanted to confirm this, we ran the queries using different quantities of rows in the batch. Using a hundred rows in each batch versus ten thousand rows per batch didn’t make too much of a difference than using a thousand rows in every batch. Therefore, we can safely conclude that it is a per-row expense.
Interestingly, it shows updates in Innodb can get over five times slower than their insertion counterparts, at least for CPU bound workloads. No wonder we end up query performance tuning for databases!
In Conclusion
The most important point to note here is that you need to be careful with partitions. The more you include, the slower your database will get, so try to avoid too many unused partitions, especially those you create in advance, thinking they will be useful in the future.
Taking into account the example above, database performance remains more or less consistent up to a hundred partitions. However, these numbers may vary significantly based on database workloads.

SQL Query Optimization Tool: The Issue with Point Queries

Databases are rather intricate systems comprising many aspects. Here, we will talk about the part that interacts with storage hardware, i.e., the storage engine. This is one of those sections that have to deal with queries, updates, transactions, compression, and concurrency.
Our previous blog was about range queries and why they are suitable for larger databases. This time, we will cover point queries and their features in terms of disk limit performance related to various operations. If you feel the need for performance tuning in your database, look for a trustworthy SQL query optimization tool, like the ones offered by Tosska Technologies Ltd.
Point Queries: Slowing Down Performance in MySQL?
Most Database Administrators are asked about the speed of the queries used in their databases. Since we are talking about point queries, these are rather time-consuming; one way of understanding their speed is by considering the following example. Suppose a hard disk of 1 TB with a disk seek time of 14ms and approximately 68 Megabytes per second of transfer speeds, like we did with range queries in the previous blog.
Next, suppose we are occupying the entire space with a single table that consists of 62.49 billion rows, each containing two integers of eight bytes separately. The manner in which this data is stored is of no consequence in our example - we will only pay attention to the part where we attempt to access said stored data in a random sequence.

Disk seeking is important when we perform random point queries. As a result, the total time taken to gain access to each data point is more than 27 years, if the system does not have any other tasks taking up process time. In other words, reading data that consist of small records that completely fill a database can take upwards of a few decades.
This is a simple example, but practically speaking, you may face different advantages or challenges during data insertion which may require the intervention of a SQL query optimization tool instead. For instance, the disk may have lower seek times, but the file system may not allow complete disk occupation. Perhaps the capacity per row is larger than 8 bytes. In the end, you may be able to save lots of time depending on the disk and system conditions, but the total time is still likely to extend over several years, at the minimum.
Fixing the Point Query Issue through Performance Tuning in SQL MySQL
Another thing to remember is that these observations are not dependent on the method of data storage employed. Because of this, some methods of performance tuning in SQL MySQL, like applying software resolutions or remedies related to data structures, will not work here.
In this case, scattering data across multiple smaller disks may partially solve your issue down the road, by pipelining the point query stream. After this, ensure that the depth is maintained at 10 - that would enable 10 disk seek operations to be carried out on ten separate disks at the same time.

However, it may get cumbersome to ensure that you perform only a single disk seek per disk at a particular instant in time. Otherwise, you can end up with the same search being performed multiple times on the same disk, which would return the same results and waste valuable time.
SQL Query Optimization Tool: Performance Tuning in SQL MySQL
After all this trouble, you will manage to complete all the point queries in around three years - just a fraction of the time it would take on a single disk, but still way too long, especially considering all the effort. To fix things further means applying parallelization at a large scale for a semblance of acceptable performance, which is not very practical.
This is why DBAs prefer range queries to handle big databases required by corporations. If you want to implement a huge database with tasks that mostly include point queries, then the only way of MySQL database and SQL is through hardware, preferably a different route than several hard disks.

SQL Plan Management Oracle- All Fundamentals You Must Know

While you make any changes in the system parameters or upgrade the Oracle database, you will often notice some highly regressed SQL performance or queries. In such cases, you don’t have to panic because it is quite obvious and happens with many whenever any plan gets changed. But the question is- how will you overcome such a nightmare? Well, it’s not that hard. You can use SQL plan management Oracle.
In case you don’t have any idea about what it is and how it could be of any help, then we are in the right place. In this blog, we will be covering every basic aspect associated with the SQL plan management and will know how it is useful in preventing query regression or performance regression.
SQL Plan Management Oracle- What is It?
A deterrent tool that lets the optimizer to control and handle SQL execution plans automatically is known as the SQL plan management. While doing so, it ensures that only known and verified plans are used by the database.
SQL plan management uses a mechanism that enables the optimizer to use it for a SQL statement. Such a mechanism is referred to as a SQL plan baseline. It’s a set of accepted plans. A plan is typically known to comprise all information associated with the plan. These consist of a SQL plan identifier, bind values, a set of hints, and an optimizer environment.
This information is used by the optimizer for reproducing an execution plan. Commonly, the database accepts a plan into the plan baseline only after it is verified and confirmed that the plan performs absolutely well,
In a nutshell, a SQL plan management Oracle is a mechanism to mitigate the risk of query regression when you upgrade to Oracle Database 11g or 12c.
Primary Elements of SQL Plan Management
Essentially, there are three key components of SQL plan management. They are as follows:
SQL Plan Baseline Capture
This component builds a SQL plan baselines that defines the accepted or trusted execution plan for all relevant SQL statements. If you are skeptical about where you can find the SQL plan baselines, then check the plan history. Plan baselines are usually stored in a plan history in the SQL Management Base. The management base needs to be found in the SYSAUX tablespace.
SQL Plan Baseline Selection
SQL plan baseline selection assures that only the accepted execution plans are used by the tool for statements having a SQL plan baseline. Moreover, it guarantees that every new execution plan is tracked in the plan history for a statement. The plan history includes both accepted and non-accepted plans. An unaccepted plan could be either rejected that would be verified bout not performant or unverified which is newly found but not verified.
SQL Plan Baseline Evolution
Such a component is meant for assessing all the unverified execution plans for a given statement in the plan history for either to be rejected or accepted.
So, these are basic components of an SQL plan management. In case you wish to fine-tune SQL queries, then you must get a SQL query optimization tool online.
What Exactly the SQL Plan Management Does?
SQL plan management oracle limits the SQL performance or query regression because of any plan changes in the database. Secondly, the tool is mainly purposed for adapting to changes gracefully.
